NBA Dataset Analysis with Python
# devtools::install_github("rstudio/keras")
# library(keras)
# install_keras() Background
Every year, millions of Americans gather around the country to watch basketball games. Being so popular, the National Basketball Association (NBA) not only makes sure these games continue to exist and entertain us but also gathers big data that helps them see patterns and trends happening in the those games. Using the Python Data Analysis Library (pandas), I will analyse some of that data to obtain meaningful insights. We won’t be running the python chunks in this post; rather, consider this as a guide to perform your own analysis using pyhton using your IDE of preference.
Data & Environment
We’ll use a dataset coming from the NBA basketball data. We’ll filter and query this data through the analysis. For now, let’s us download the libraries and functions we’ll need for such analysis.
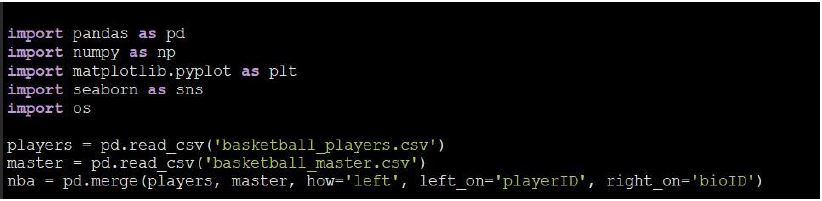
Notice how we can abbreviate the packages using the keyword “as”; this is especially helpful since in Python we need to call the package and then the specific function each time (e.g.: “pd.merge(\(something\))”).
I also like to bring your attention to the last line of code in that chunk, where we create our dataset “nba”. Notice how we’re Using SQL? Let us remember the difference between joins and unions. Joins combine to tables by columns, where as union combines it by rows. So what did we do in that line? If you thought of join, you’re right. And we can see another key word “left”, as in “left join. In StackOverflow, we found a succint definition of the different types of joins available:”A. INNER JOIN: returns rows when there is a match in both tables. B. LEFT JOIN: returns all rows from the left table, even if there are no matches in the right table. C. RIGHT JOIN: returns all rows from the right table, even if there are no matches in the left table. D. FULL JOIN: It combines the results of both left and right outer joins."
Explotory Data Analysis
Doing EDA on Python is very easy and straight forward. Let’s start with the descriptive statistics part.
If we want to know the mean, median, or maximum of points scored by player, we can use the following commands:
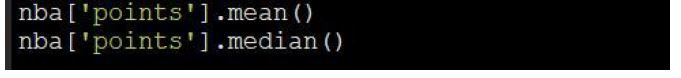

We will soon see that the Mean = 492.14, Median = 329.0, and the Maximum points scored = 4029 by Wilton Norman Chamberlain on 1961. Quite easy!
Graphical summaries are very straightforward too. Using the function boxplot() of the package Seaborn (remmber we saved it as “sns”), we can see the distribution of points, assists, and rebounds.
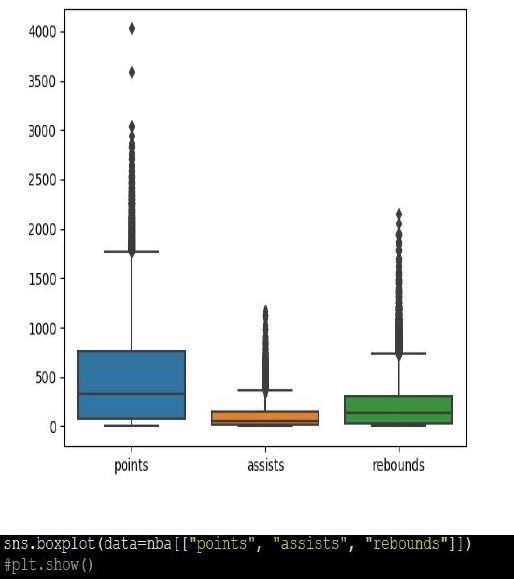
Insights
One question we might ask how the median of points have changed throught time. To do this, we’ll have to group the rows in the dataset by year.
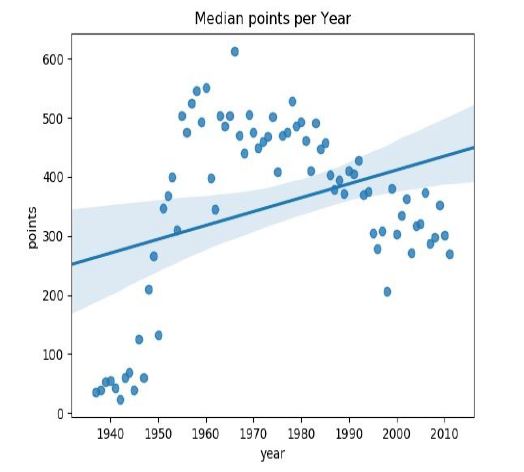
Here we used a regular plot from the Seaborn package, we added a title, chose the variables from the axis, and reset the index.
One more question that we can ask is if there Are players that are much more efficient (points per attempt) than others. In order to answer this question, we will focus on the first 10 players with the most points.

We’ll then get a new subset of data that goes like this:
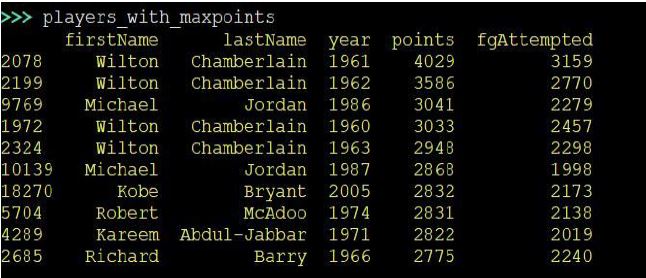
Now we add a new column that calculates the difference between points and attempt. A higher difference indicates that the player achieve more points with less attempts, which in turn means he was more efficient.

To find out the top 5 most efficient players, we sort the table by that difference, and we can get those results!

Moving on with our analysis, are there any players that are exceptional across many categories? For this question we’ll look at four categories: points, rebounds, steals, and blocks. We’ll add up all points each player has for this category and call the sum “ranking”.

Notice that we created the ranking with a very simple approach: adding up points accross the categories. This is not very accurate since one player may have 1,000 points of rebounds but 1 point of steals, and would come out as exceptional player. But luckily, choosing the top 5 will kind of ease this problem.
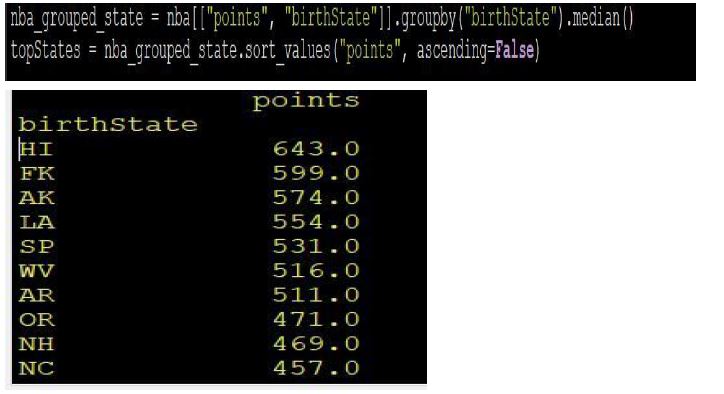
Now let’s check if there’s a higher mean of points attending to the hometown of the players. To do this, we group players by hometown and calculate the mean of points.
Lastly, we’ll see if there’s a trend in which three-points throws increased in similarity. To do this we must see if there’s a correlation between time and number of three points attempted. We’ll see if this is the case by creating a scatter plot.
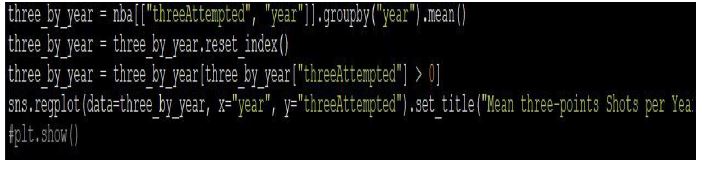
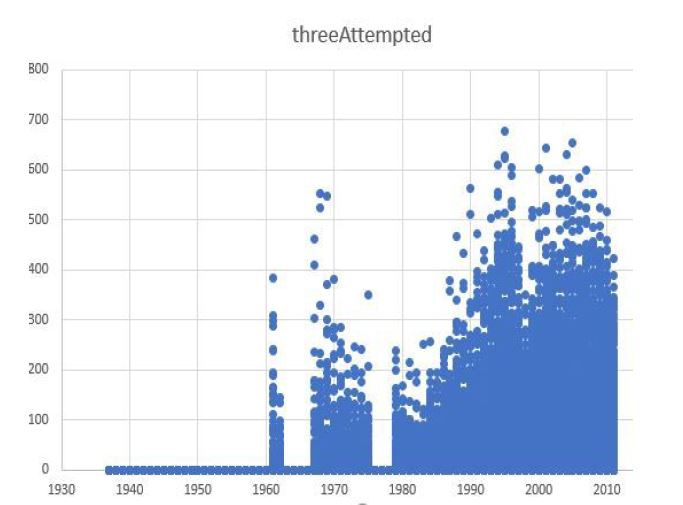
Here we see that indeed there’s a turning point in the attempts, and it all started in the 80’s reaching its max in in the late 90’s.